8. Relevance of Documentation
A map is not the territory it represents, but, if correct, it
has a similar structure to the territory, which accounts for its
usefulness. If the map could be ideally correct, it would include,
in a reduced scale, the map of the map; the map of the map, of the
map; and so on, endlessly, a fact first noticed by Royce.
—Alfred Korzybski, Science and Sanity, Chapter IV, p. 58.
The relevance of documentation, \(R_{doc}\) deteriorates, whenever
the source code is changed, but the documentation is not updated.
The rate of deterioriation for a given piece of documentation
increases with
- the distance to the source code, \(D_{source} \ge 0\)
- the inavailability of a documentation editor, \(I_{edit} \ge 0\)
- the necessary effort for synchronization with the master document,
\(E_{sync} \ge 0\)
- the inertia of the human components \(H_{inertia} \ge 1\)
involved.
The likeliness of relevance of a given piece of documentation, \(L_{R_{doc}}\) is therefore:
(8.1)\[\begin{split}& L_{R_{doc}} = \left( \left( \frac{1 + ( {D_{source}} + {I_{edit}} + {E_{sync}} + {H_{inertia}} )}{2}\right)\cdot{H_{inertia}} \right)^{-1}\\\end{split}\]
8.1. Introduction
The relevance of documentation is a measure of how similar the
structure of the documentation is to the structure of the source code.
This is closely connected to the map–territory relation of General
semantics. A thorough understanding of this principle really helps
manage the expectations of what documentation of source code is, is
not and can be. The fact, that documentation can never be accurate in
the sense of a bijective mapping, does not mean it can not be helpful
– even essential – for a human brain to construct an appropriate
model.
A major problem of software documentation arises from the fact, that
the documented source code is often not available to the
reader. Imagine, being given the following instructions for obtaining
an item from a certain location:
- go straight
- go left
- look at the sign, that says “Menu”
- order the second item
- bring it back
|
However, you are only given access up to a fence with a locked gate,
where you can see the straight part of the road and the left turn, but
you cannot see the menu. At the locked gate, there is only a sign with
yesterday’s menu. Now you are supposed to predict what the second item
on today’s menu will be without being able to examine the actual menu
(see figure 8.1). It is pretty obvious,
that this cannot be reliably done, especially if the menu is changing
daily to whatever the chef feels like.
This describes the situation developers often find themselves in when
working with proprietary software. But even when source code access is
available – since they are incidentally the developer, who works on
it – they are still expected to produce documentation for people that
cannot understand the code; i.e., these people – who may just as well
be future versions of the developer himself – choose to stay at the
fence and refuse to walk through the gate. So developers may write
things like: “And then look around in the source code, to find out
what the real state of affairs is at any given moment.” However, they
cannot expect any particular reader to make the effort. See the
Sphinx and Doxygen document generators in section 14, Sphinx Documentation Generator for
excellent examples, how the entire source is included for
cross-referencing.
So, how much interest can you muster for the utterly boring
description of a treasure hunt for an unspecified treasure in a
country you don’t know and don’t have the means to ever get to?
For me, that is one trivially self-evident answer to questions like
“What’s with the aversion to documentation in the industry?”. The
rapid deterioration of relevance for documentation during the
development phase being another.
However, having no documentation at all is not a viable option and
there are certainly ways to reduce the effort and increase the
relevance of documentation.
8.2. Source and documentation management
Derived from the above equation, the best likeliness of relevance of a given piece of documentation is achieved when all
deterioration factors, \({D_{source}}\), \({I_{edit}}\), \({E_{sync}}\), \({H_{inertia}}\) are at a
minimum, which makes \(L_{R_{doc}} = 1\).
To discuss the likeliness of relevance of a given piece of documentation, it is necessary to define a model, which
explains the parameters in their respective context (see
figure 8.2).
Note
The required editor for a change is just one of a possible
multitude of appropriate editors. It is not necessarily the
preferred editor of a specific programmer (see
figure 8.3).
8.3. Minimum Distance to Source Code
A distance to source code, \({D_{source}}\) of \(0\) corresponds to the
principle “the source is the documentation”, i.e., there is no
additional documentation for the source code. Substituting \({D_{source}}\)
by \(0\) in equation (8.1)
results in:
(8.2)\[\begin{split} & \left( \left( \frac{1 + ( {I_{edit}} + {E_{sync}} + {H_{inertia}} )}{2}\right)^{H_{inertia}} \right)^{-1}\\\end{split}\]
In this case, the source editor and the documentation editor are
necessarily the same and therefore \({I_{edit}}\) can be eliminated from
equation (8.2):
(8.3)\[\begin{split}& \left( \left( \frac{1 + ( {E_{sync}} + {H_{inertia}} )}{2}\right)^{H_{inertia}} \right)^{-1}\\
& L_{R_{doc}} = ( 1 + ( {D_{source}} + {E_{sync}} )^{H_{inertia}} )^{-1}\\\end{split}\]
When the source code changes are made to the master source file,
\({E_{sync}}\) is also \(0\) and equation (8.3) is reduced
to:
(8.4)\[\begin{split} & \left( \left( \frac{1 + {H_{inertia}}}{2}\right)^{H_{inertia}} \right)^{-1}\\\end{split}\]
Without automatic documentation generators that have to be triggered
manually, human inertia \({H_{inertia}}\) is \(1\) and equation
(8.4) is reduced to \(1\):
(8.5)\[\begin{split}& \left( \left( \frac{1 + 1}{2}\right)^{1} \right)^{-1} = 1\\\end{split}\]
So it seems, that the only time, documentation is guaranteed to be
entirely relevant, is if there is none. In all other cases,
documentation and source strictly abide by the properties of the
map–territory relation.
However, there are tools like grep(1), ctags(1), etags(1), cscope(1),
even Sphinx and doxygen, also (reluctantly) IDEs like Eclipse,
which extract meta-information from undocumented source code to
provide hyper linking facilities, which is in itself an extremely
useful part of any documentation.
Other Generators produce Nassi-Shneiderman diagrams (flowcharts,
activity diagrams), dependency graphs, etc.
Therefore the principle “the source is the documentation” is
actually not so blunt or ridiculous as it may sound at first.
However, since automatically generated documentation requires a
compilation step that may require manual triggering, \({H_{inertia}}\) may
quickly become a signifanct factor.
8.4. Inertia
In the eternal sunshine of the spotless mind, each relevant source
modification triggers a documentation update (see figure 8.4).
But this is only true, when no human components are involved in the
process of deciding, whether a source change is relevant for a
documentation update. And this can only be the case when no manually
created documentation parts have to be maintained. An example for
this is the initial documentation produced by generators like
Sphinx and Doxygen.
However, there is usually a more or less complex update decision
process involved, which potentially results in increases of \({I_{edit}}\)
and human inertia \({H_{inertia}}\) (see figure 8.5).
The decision process in state Update Decision looks somewhat like
the activity diagram in figure 8.6. Feel free to add an infinite number of excuses for not
updating the documentation or postponing the update indefinitely.
8.5. Single Editor for Source and Documentation
When the documentation editor is the same as the source editor, the
decisions about using or installing a separate documentation editor
are removed. Therefore the result “not possible” is no longer
returned (see figure 8.7).
Consequently, the state machine for editing sources is also reduced.
The state “Increment Inavailability” is removed and therefore
\({I_{edit}}\) is no longer incremented (see figure 8.8).
Therefore \({I_{edit}}\) is always \(0\) and equation
(8.1) is reduced to:
(8.6)\[\begin{split}& L_{R_{doc}} = \left( \left( \frac{1 + ( {D_{source}} + {E_{sync}} + {H_{inertia}} )}{2}\right)\cdot{H_{inertia}} \right)^{-1}\\\end{split}\]
Note
Please, note, that in addition to a documentation editor,
there may be separate documentation generators required to produce
some form of final documentation (e.g., SVG, PNG, JPEG, HTML, PDF).
However, the lack of these does not contribute to the deterioration
of relevance, as long as the documentation source is updated.
If it is found, that the update of a piece of documentation without
a visual representation created by the documentation generator is
not possible, this decision may have to be revisited.
8.6. Synchronization
When there is a single file on just one computer, there is obviously
no synchronization necessary and therefore \(E_{sync} = 0\).
Sometimes it is better to copy a project directory and work on the
copy so that others are not disturbed by the intermediate states of
development. That is called a branch or working on a branch. The
original project file is the master.
As long as nothing leaves the branch directory, the documentation is
not affected by the effort necessary for synchronizing the branch with
the master. It is only, when e.g. a binary version from the branch is
delivered to a production system, that the master documentation
becomes less relevant until the branch with all documentation changes
is synchronized (merged) with the master. This is the situation when
\(E_{sync}\) becomes \(> 0\).
Human forgetfulness and general sloppiness are major factor for
discrepancies, where branches are left to rot on flash drives and,
newer versions are overwritten by older versions, etc.
This is why the process is nowadays highly automated by distributed
version control systems (DVC).
DVCs are quite good, but sometimes you don’t want to check in changes,
that need some final touch. In that case, you are back to copy or
remote copy (scp(1), rsync(1)). So all other stages are still useful:
- backup file
- diff(1), patch(1), diff3(1)
- scp(1), rsync(1)
- VCS
- DVCS
8.6.1. qs-gen-sync.pl (.sync.rc)
There are two aliases for backup and restore:
- bsy
- send stuff to remote host
./sync.sh --backup
- rsy
- get stuff from remote host
./sync.sh --restore
Generate initial .sync.rc:
8.6.2. diff3
|:todo:| finish description of diff3(1)
diff3 doc/index.rst README.txt doc/overview.rst
8.7. Battling Human Inertia
The only way to defeat human inertia, \({H_{inertia}}\), is automation.
See also figure 8.9
|:todo:| finish description of scripting sh(1), make(1)
- make/scripts are memory banks for knowledge
8.7.1. Integrated Development Environment
An IDE strives to be an integrated solution for cross-referencing,
build automation, generated documentation.
In that sense, emacs(1) can also be classified as an IDE.
Eclipse is ridiculously hard to extend out of the box with plug-ins
written in Java. E.g., in a forum question from 2016 about how to
extend the default Java editor, somebody just wants to add a few
keywords to the Java editor and gets links to a PDF slideshow about
JDT and to Xtext. Neither are anywhere near trivial.
EASE does provide integration of script engines into Eclipse
giving access to the workbench. This engine may be able to handle
couple of keywords, if it can be added to Eclipse extension points
(hooks), which needs to be researched |:todo:|. So in 2017 eclipse
announces another convoluted overstructured object oriented
integration, which still does not reach easily into an editing
buffer (see also Internal and External Editors).
See also
https://stackoverflow.com/questions/26912785/eclipse-jdt-syntax-highlighting-of-constants
from 2014, which is still unanswered. The answers in
https://stackoverflow.com/questions/13802131/in-an-eclipse-plugin-how-can-i-programmatically-highlight-lines-of-codes-in-the,
give a variety of strategies to follow, but none of the answers gives
a step-by-step example.
Here is another failed attempt
https://www.eclipse.org/forums/index.php/t/489221/ for adding some
highlighting to the Eclipse editor.
All in all Eclipse has still not reached the efficient state of the
art provided by emacs(1) for decades. emacs(1) can be extended
ridiculously simple with a multitude of tools glued together by Elisp.
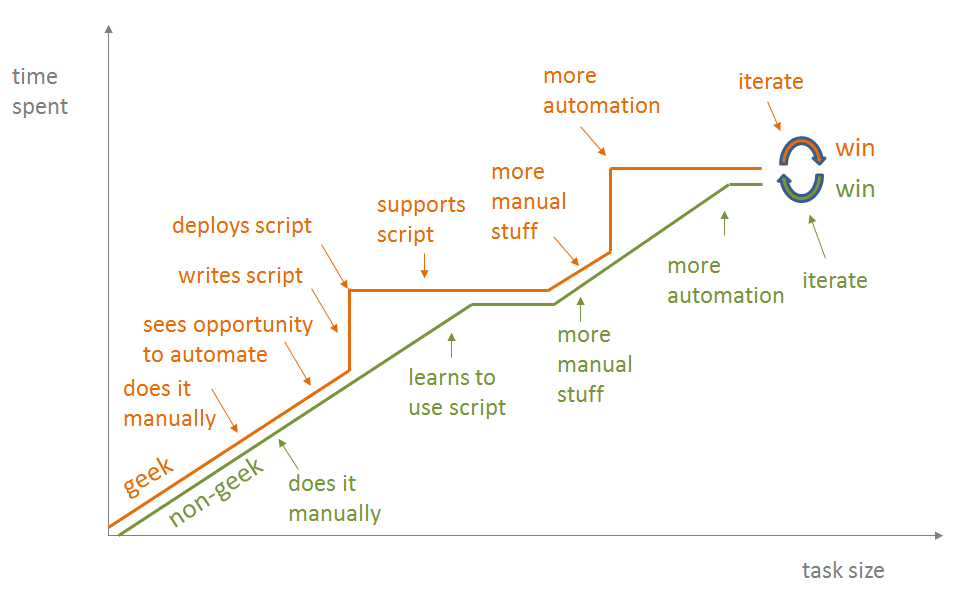
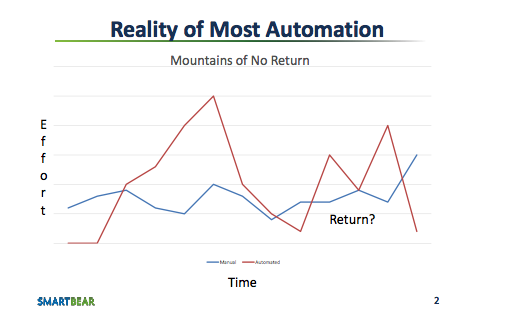
As discussed in the article Using Automation to Assist – not replace
– Manual Testing, automating entire workflows is very much
ineffective (see figure 8.10).
In that context, a tightly integrated IDE – like Eclipse or
Visual Studio – is the ineffective attempt to provide an entirely
automated workflow in a one-size-fits-all manner.
In contrast, the loosely integrated approach with emacs(1) and tools
provides a framework for task automation which can adapt to a variety
of workflows.
A monolithic IDE usually has a plethora of cryptic configuration
settings to provide some sort of rudimentary flexibility
(customization), whereas the tool based IDE allows full
modification of each automation step down to the code level.