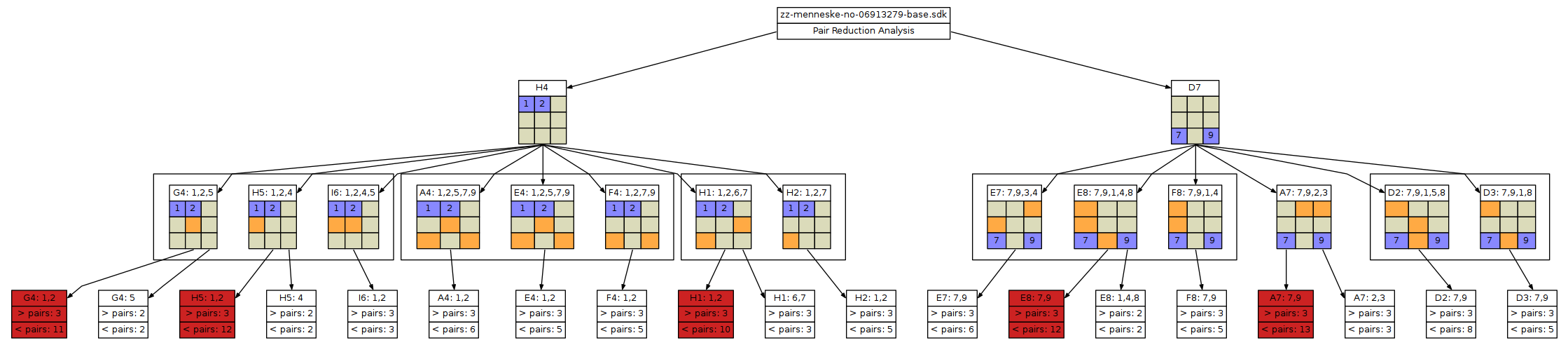
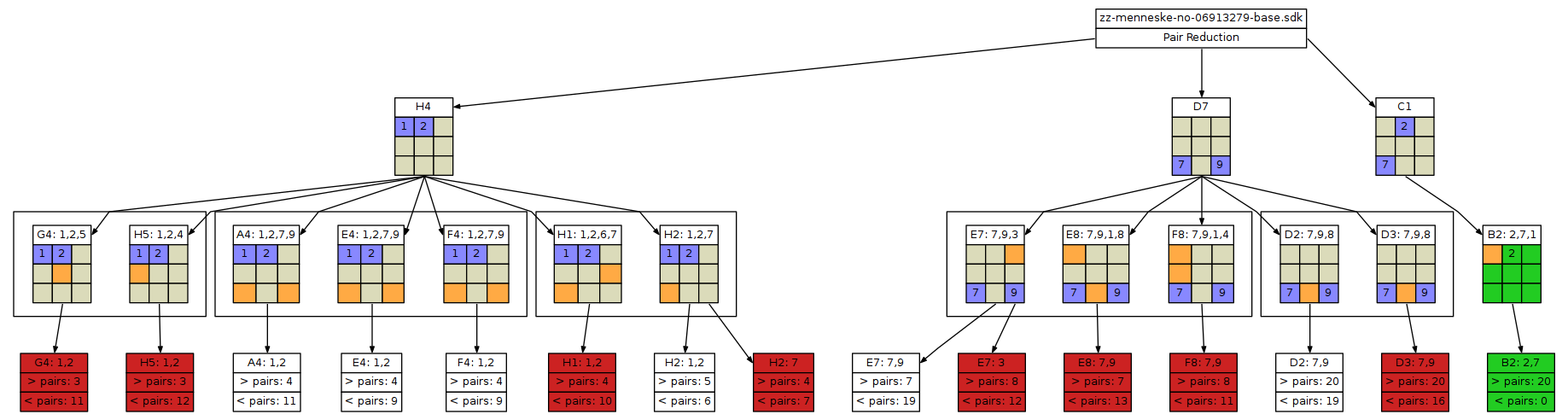
DIS # I8: 3,9 # B1: 1,2 => CTR => B1: 6
DIS # I8: 3,9 + B1: 6 # A2: 1,2 => CTR => A2: 5,9
DIS # I8: 3,9 + B1: 6 + A2: 5,9 # B5: 1,2 => CTR => B5: 3,8
DIS # I8: 3,9 + B1: 6 + A2: 5,9 + B5: 3,8 => CTR => I8: 2,7
DIS I8: 2,7 # G7: 5 # G4: 6 => CTR => G4: 1,8
DIS I8: 2,7 # G7: 5 + G4: 1,8 # A4: 2,9 => CTR => A4: 1,3
DIS I8: 2,7 # G7: 5 + G4: 1,8 + A4: 1,3 # A5: 2,9 => CTR => A5: 1,3,6
DIS I8: 2,7 # G7: 5 + G4: 1,8 + A4: 1,3 + A5: 1,3,6 # C5: 2,9 => CTR => C5: 6
DIS I8: 2,7 # G7: 5 + G4: 1,8 + A4: 1,3 + A5: 1,3,6 + C5: 6 => CTR => G7: 3,9
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 # E9: 2,6 => CTR => E9: 1,3,8
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 + E9: 1,3,8 # F9: 2,6 => CTR => F9: 1,3,8
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 + E9: 1,3,8 + F9: 1,3,8 # F7: 3,9 => CTR => F7: 2,4
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 + E9: 1,3,8 + F9: 1,3,8 + F7: 2,4 # A8: 4 => CTR => A8: 2,7
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 + E9: 1,3,8 + F9: 1,3,8 + F7: 2,4 + A8: 2,7 # B1: 1,2 => CTR => B1: 6
DIS I8: 2,7 + G7: 3,9 # F8: 3,9 + E9: 1,3,8 + F9: 1,3,8 + F7: 2,4 + A8: 2,7 + B1: 6 => CTR => F8: 2,4,6
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 # B8: 2,4 => CTR => B8: 3,6
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 # B6: 2,4 => CTR => B6: 6,8
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 # D7: 2,4 => CTR => D7: 7,9
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 # F7: 9 => CTR => F7: 2,4
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 # B1: 2,4 => CTR => B1: 1,6
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 + B1: 1,6 # A8: 3,6,7 => CTR => A8: 2,4
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 + B1: 1,6 + A8: 2,4 # A2: 2,4 => CTR => A2: 9
DIS I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 + B1: 1,6 + A8: 2,4 + A2: 9 # E1: 2,3 => CTR => E1: 5
PRF I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 + B1: 1,6 + A8: 2,4 + A2: 9 + E1: 5 => SOL
STA I8: 2,7 + G7: 3,9 + F8: 2,4,6 + B8: 3,6 + B6: 6,8 + D7: 7,9 + F7: 2,4 + B1: 1,6 + A8: 2,4 + A2: 9 + E1: 5